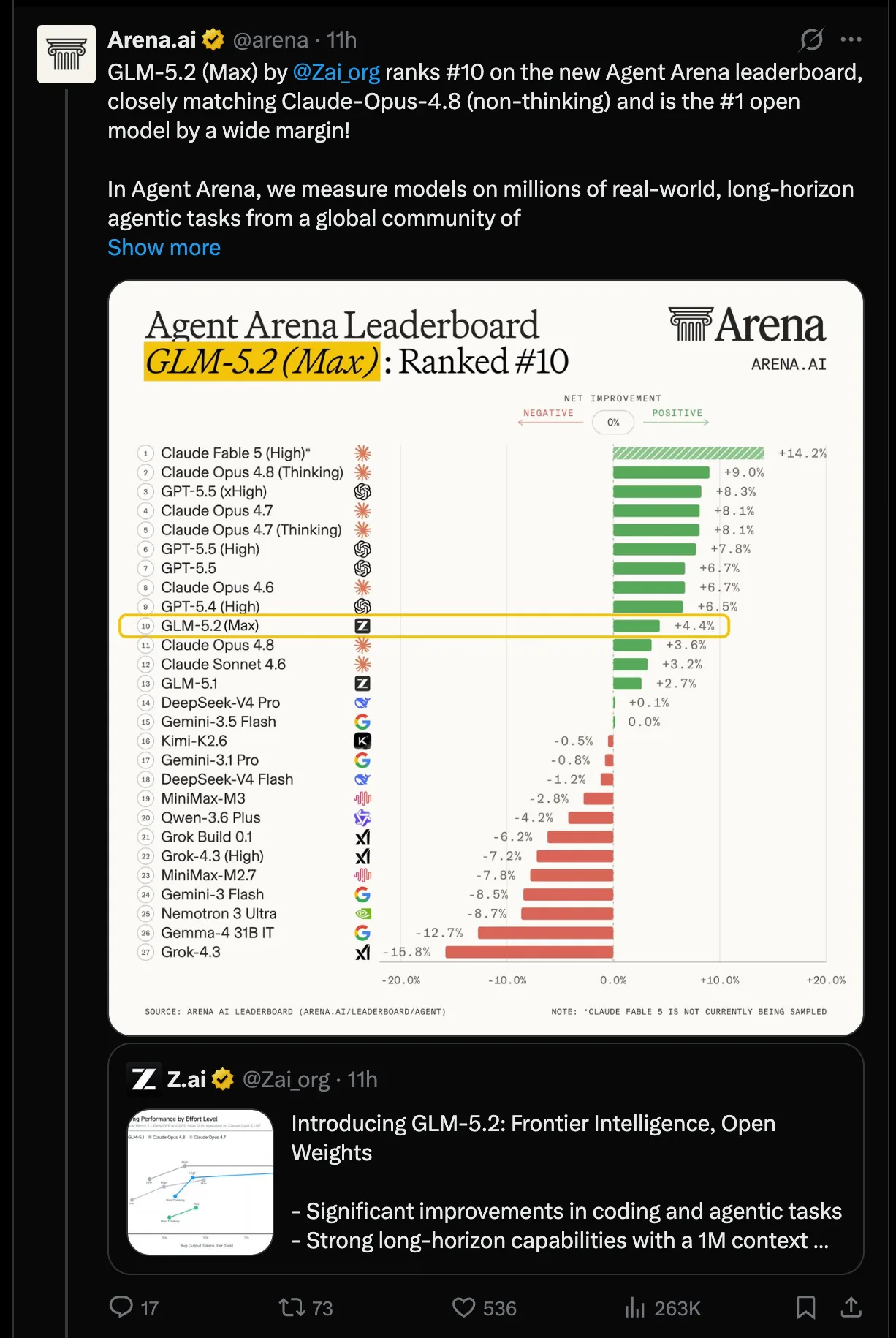
Open Source
Linux Foundation lanza Akrites contra exploits hallados por IA
Amazon, Anthropic, OpenAI, NVIDIA, Microsoft, Red Hat y otros 14 actores arman un SIRT compartido y un proceso CVD estandarizado para parchar bugs encontrados por LLM en software crítico.
Phoronix Tests