IA
NVIDIA AI-Q 2.0 llega a Oracle Cloud con un Blueprint listo en 25 minuto
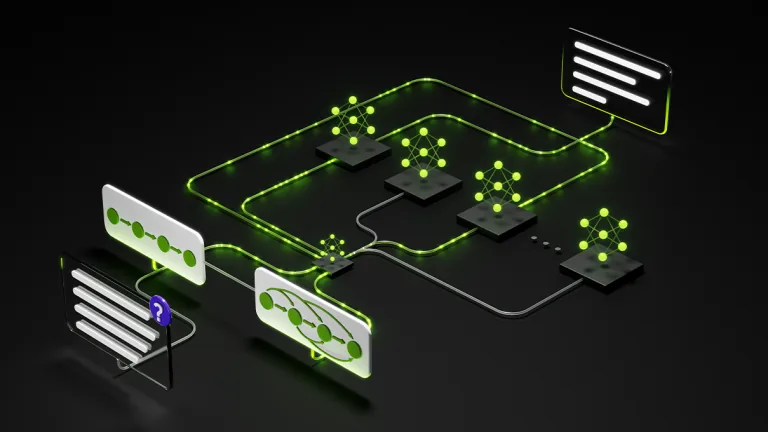
El blueprint open source para agentes de IA de NVIDIA ya tiene una receta lista para Oracle Cloud Infrastructure: Terraform crea el clúster OKE y Helm instala backend, frontend y PostgreSQL.
NVIDIA Developer