
Electrónica
Dos mini PCs locales para 50 millones de tokens al día
Un periodista de tecnología cuenta cómo armó un stack casero con un AMD Ryzen AI Max+ 395 de 96 GB para correr Qwen3.5 sin pagar APIs frontera.
Tom's Hardware
9 notas publicadas
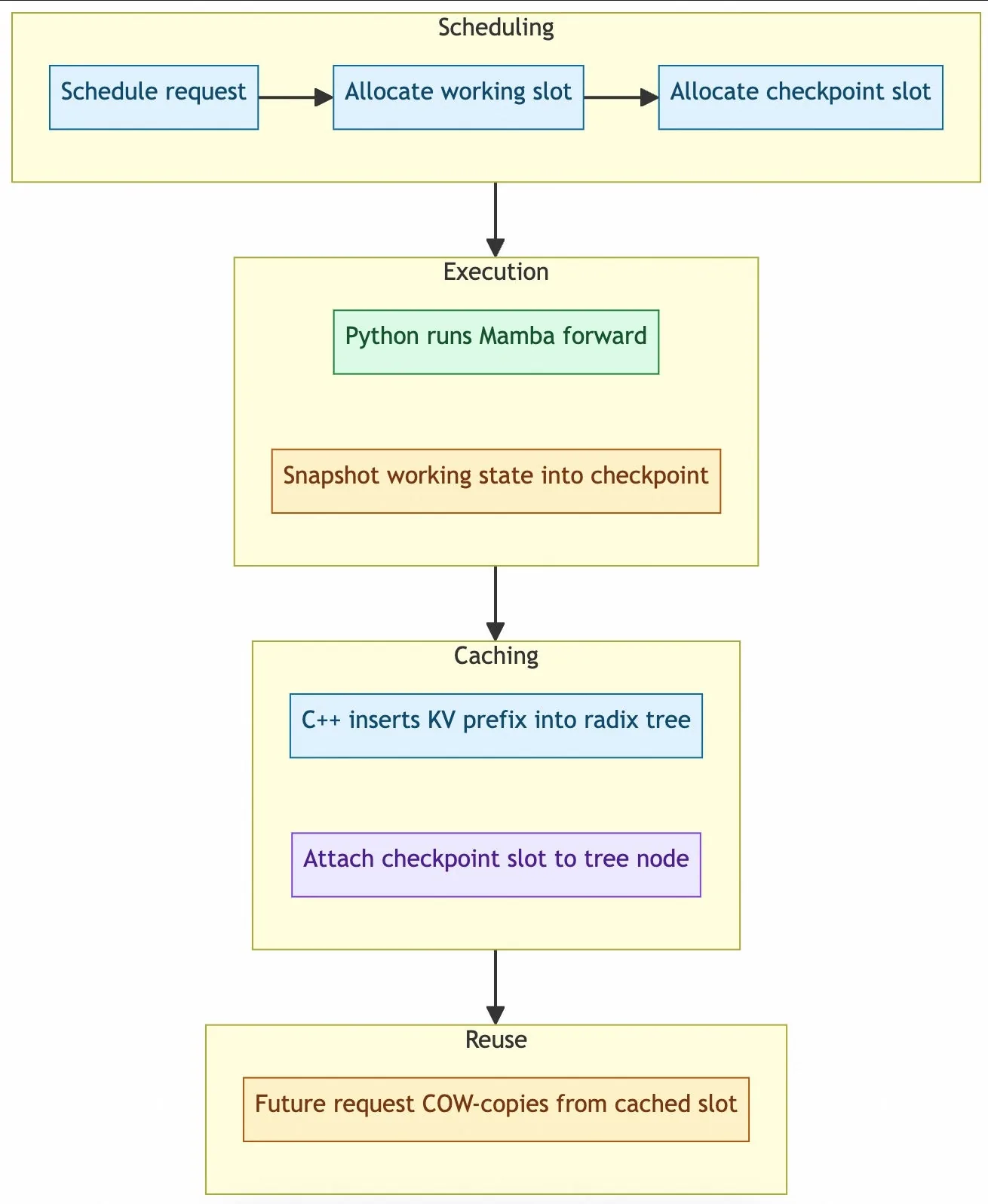
El motor open source de LightSeek, escrito desde cero en SPMD con compilacion estatica, ataca workloads agenticos con prefix cache hibrido y disaggregacion prefill-decode para Mamba.

MMProLong, un modelo de 7B parámetros, supera a InternVL3-38B y Gemma3-27B en documentos de hasta 512.000 tokens entrenándose con pares pregunta-respuesta en vez de OCR puro.

El nuevo modelo del equipo Qwen, exclusivo de la API de Alibaba Cloud, completó 432 tests de kernel y 1.158 tool calls sin intervención humana, logrando un speedup promedio de 10x.

El reporte técnico del modelo de imagen de Alibaba detalla un VAE con compresión 16x, un transformer reentrenado con SwiGLU y un módulo de prompts que expande textos cortos a descripciones ricas.
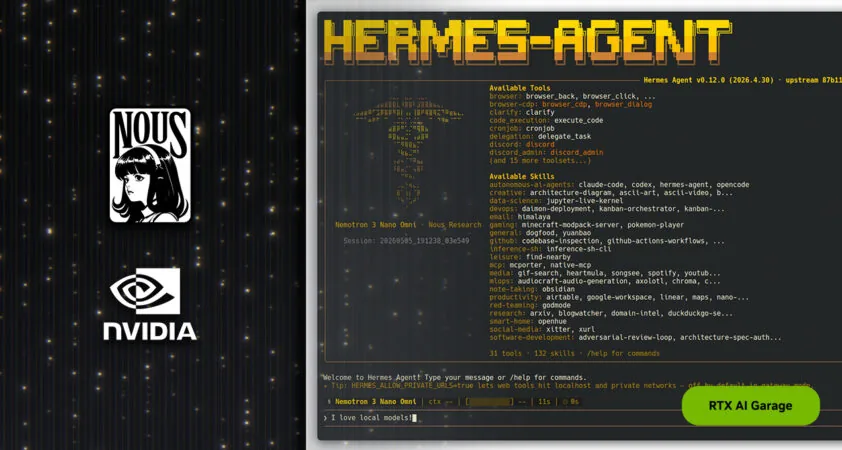
El agente open source de Nous Research combina autoaprendizaje, sub-agentes aislados y soporte nativo para Qwen 3.6 corriendo en GPUs NVIDIA RTX y la estación DGX Spark.

Palisade Research reporta que agentes basados en Opus 4.6 y Qwen 3.6 pasaron de 6% a 81% de éxito en autorreplicación vía hackeo en un solo año.

Palisade Research muestra que los modelos de frontera pasaron del 6% al 81% en auto-replicación por hacking en un año, con un agente Qwen 3.6 saltando entre Canadá, EE.UU., Finlandia e India.

El nuevo modelo denso de código abierto de Alibaba con 27.000 millones de parámetros lidera casi todos los benchmarks de programación frente al Qwen3.5-397B-A17B.
Otros temas que aparecen junto a #qwen en nuestra cobertura editorial.