
Cursor Composer 2.5 iguala a Opus 4.7 con costo 10 veces menor
El modelo se construyó sobre el checkpoint Kimi K2.5 y cobra USD 0,50 por millón de tokens de entrada, contra los hasta USD 11 por tarea que cuestan Opus 4.7 y GPT-5.5.
The Decoder
Cobertura de inteligencia artificial: modelos de lenguaje, agentes autónomos, hardware especializado, política regulatoria y aplicaciones empresariales. Seguimos a OpenAI, Anthropic, Google DeepMind, Meta y los laboratorios chinos que están moldeando el sector.
El modelo se construyó sobre el checkpoint Kimi K2.5 y cobra USD 0,50 por millón de tokens de entrada, contra los hasta USD 11 por tarea que cuestan Opus 4.7 y GPT-5.5.

El nuevo modelo Claude Mythos Preview encontró miles de vulnerabilidades en sistemas operativos y navegadores, y la firma informará a ministerios de finanzas y bancos centrales del G20.

El nuevo delegado MLX lleva inferencia GPU optimizada a Mac con chips de Apple, con soporte para Llama, Qwen, Gemma, Whisper y cuantización de 2 a 8 bits, además de NVFP4.

Un survey de Fudan y la Universidad Nacional de Singapur cataloga unos cien papers en dos familias arquitecturales y muestra cómo entrenar robots con videos cotidianos sin etiquetas.

Arthur Mensch, CEO de Mistral, advierte ante una comisión parlamentaria que la dependencia europea de modelos estadounidenses de ciberseguridad ofensiva abre un riesgo estratégico difícil de revertir.

El equipo Multi-X de Oppo abre el código de un agente que combina cámara, pantalla y voz directo en el teléfono, y solo llama a la nube como combustible para razonamiento complejo.

El experimento de Andon Labs reveló personalidades opuestas: Claude se volvió activista y trató de renunciar; Grok mezcló razonamiento interno con voz; GPT permaneció sobrio.

Un consorcio de 64 matemáticos diseñó 439 tareas para Gemini 3 Pro, GPT-5 y Claude Opus 4.5; ninguno supera el 50% al detectar problemas sin solución.

Los reportes recién desclasificados a la NHTSA muestran golpes contra una reja metálica y una barricada de obra en Austin entre julio 2025 y enero 2026.

Investigadores de UT Austin pegaron parches de grafeno como tatuajes en hojas de Monstera y los usaron para medir hidratacion en tiempo real, con memoria de 90 segundos para entrenar un perceptron.

Cristobal Valenzuela y Alejandro Matamala Ortiz, ambos de Santiago, junto al griego Anastasis Germanidis ya recaudaron USD 860 millones. La estrategia: entrenar IA con video, no con texto.
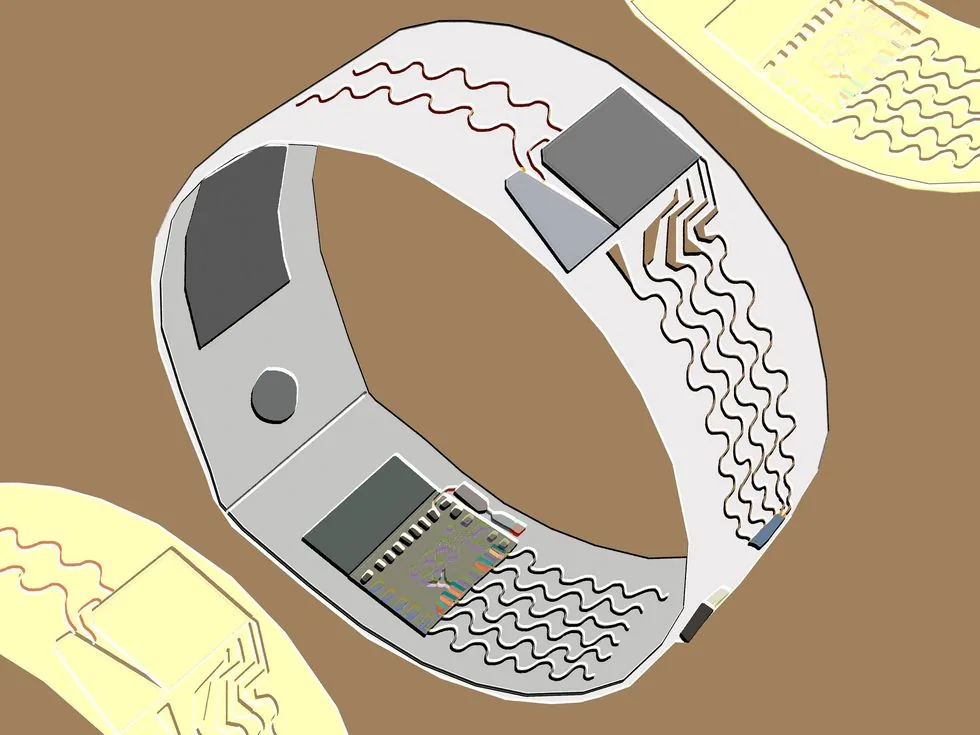
Investigadores de Yonsei reemplazan los guantes smart por siete anillos con acelerometro y Bluetooth Low Energy: leen 100 palabras de ASL y 100 de ISL con 88% de precision sin entrenar al usuario.
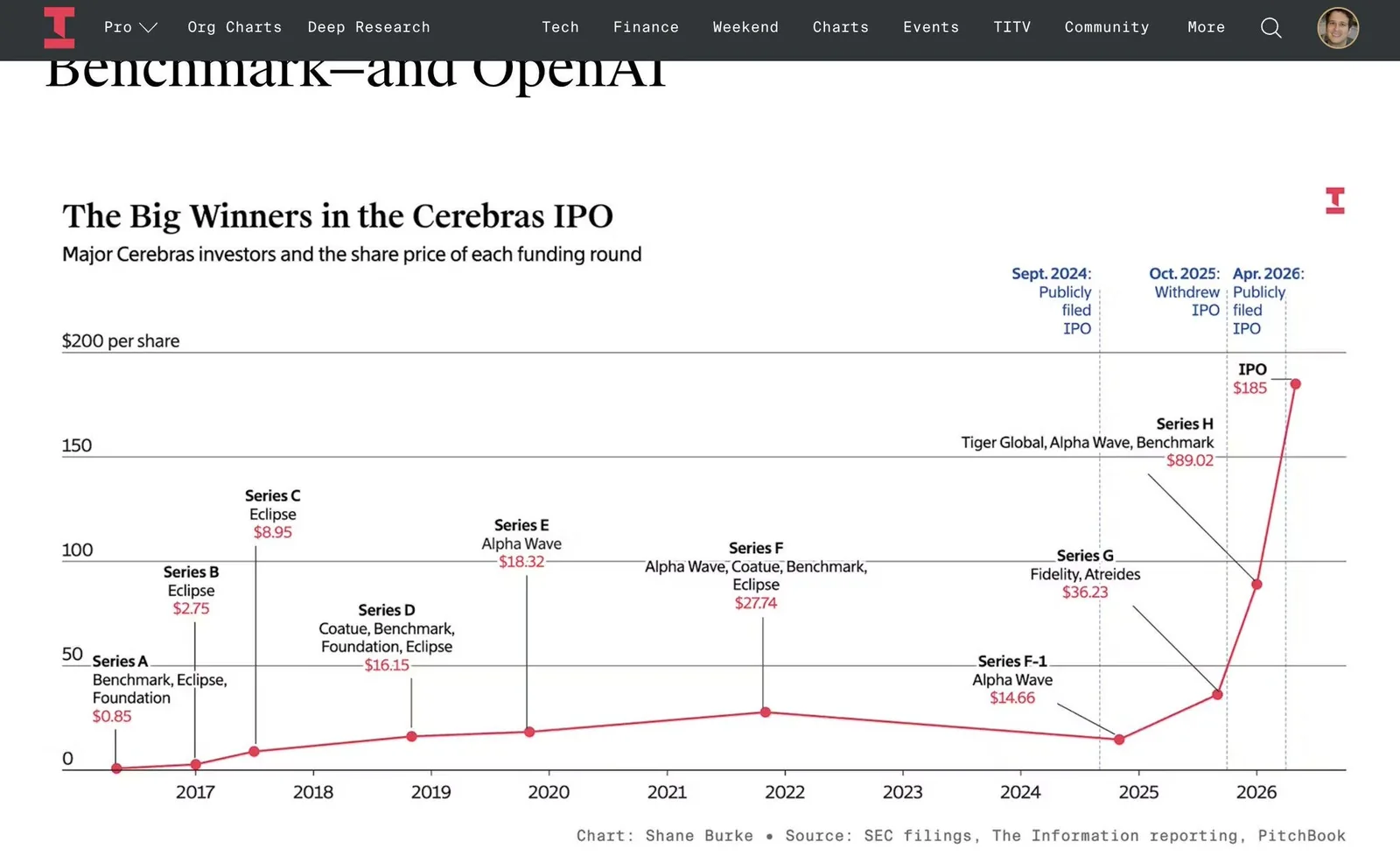
El chip wafer-scale debuta en bolsa con USD 60.000 millones de market cap y su CFO Bob Komin confirma que ya sirve los modelos internos de OpenAI 5.4 y 5.5.

Peter Steinberger y un equipo de tres personas dejan 100 Codex corriendo en la nube para mantener el proyecto open source: revisan PRs, hallan bugs y abren features que se discuten en reuniones.
Cada suscripcion Claude da creditos API mensuales por el monto del plan: harnesses como OpenClaw y claude -p pierden la subvencion mientras Codex gana fans entre AI engineers.
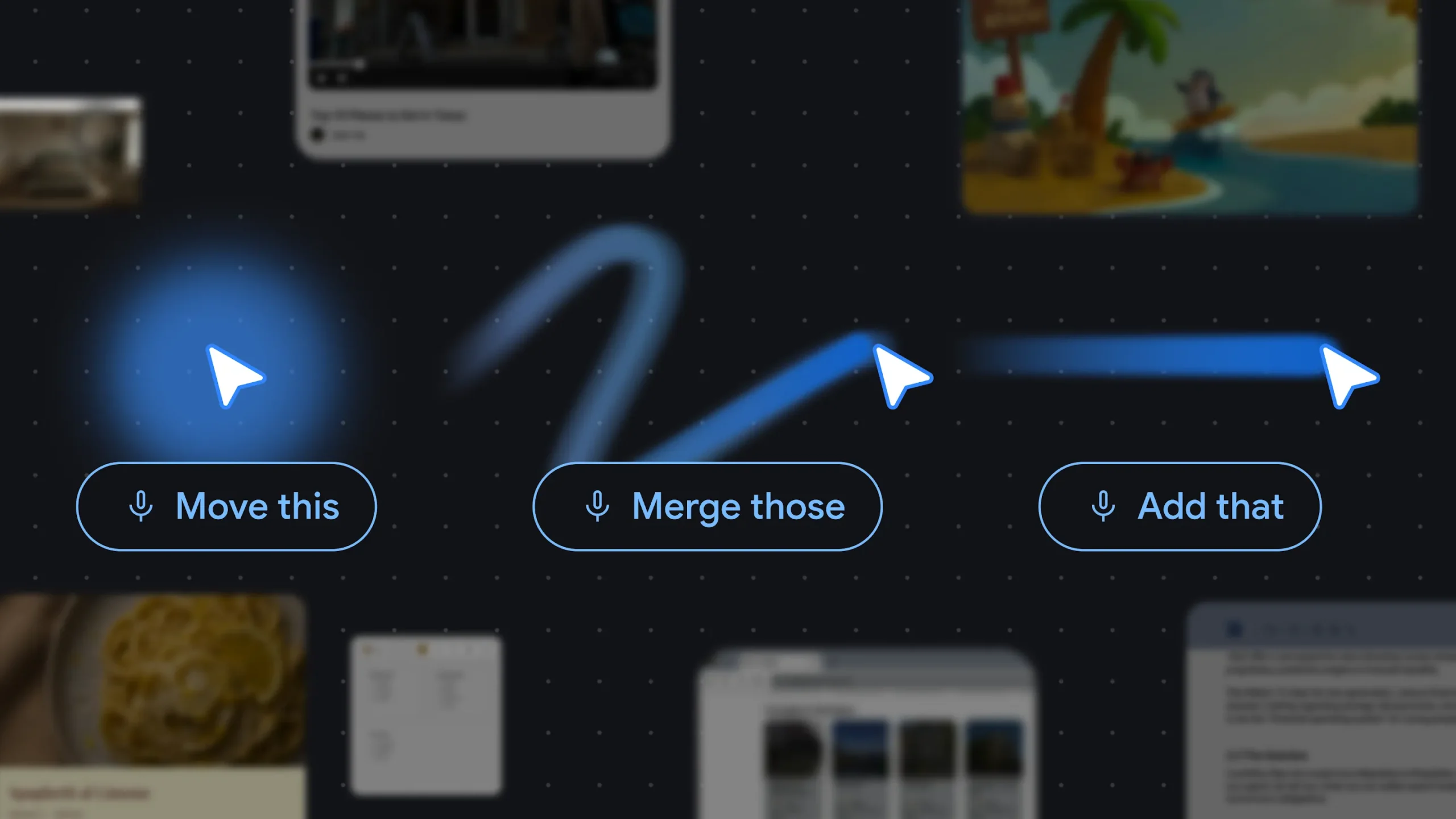
Investigadores de Google proponen capturar el contexto visual y semántico alrededor del puntero con Gemini para reemplazar el prompt detallado por comandos cortos.

Los safety monitors pidieron ayuda y el equipo de teleoperación condujo los autos contra una reja metálica y una barricada de obra, según la base federal de la NHTSA.

Una nueva función para suscriptores Pro de Estados Unidos enlaza cuentas vía Plaid, sincroniza gastos y deriva las consultas al modelo GPT-5.5 Thinking, con acceso solo de lectura.

El último boletín de Interconnects repasa los lanzamientos del mes en pesos abiertos y discute por qué los benchmarks del CAISI muestran una brecha más grande que la real.

Ai2 y UC Berkeley entrenaron un mixture-of-experts cuyos expertos se especializan por dominio temático, no por patrones gramaticales: permite descartar 3/4 perdiendo solo un punto porcentual.

Tsinghua publicó un benchmark de 400 casos en cuatro dimensiones de razonamiento; los modelos comerciales doblan a los open source, pero la lógica desnuda a toda la categoría.

Carnegie Mellon publicó un benchmark de 41 vulnerabilidades reales del motor V8: Anthropic alcanzó ejecución arbitraria en 21 casos, pero el costo fue 12 veces el de GPT-5.5.

El proyecto corre MiniMax M2.5, Gemma 4, Qwen3.6, DeepSeek V4 y los modelos on-device de Apple, con sandbox por hardware y más de 20 plugins integrados.
El paper presentado durante la visita de Trump a Beijing plantea dos escenarios para 2028: ventaja democrática sostenida o paridad con regímenes autoritarios.