
IA
Cuantización FP8: Optimiza modelos con NVIDIA TensorRT
Aprende a exportar modelos cuantizados mediante ModelOpt a ONNX y compílalos con TensorRT para maximizar el throughput y reducir el uso de VRAM en GPUs NVIDIA.
NVIDIA Developer
5 notas publicadas
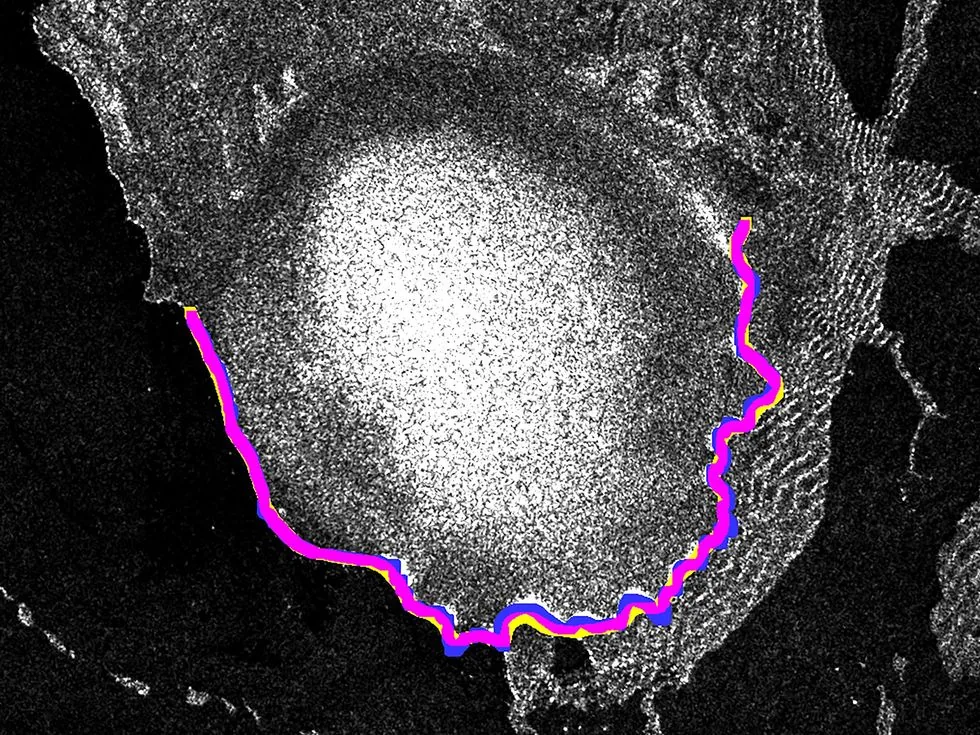
Un innovador enfoque permite que los modelos de IA se adapten a nuevas regiones con datos mínimos, mejorando la precisión del seguimiento climático global.

El nuevo modelo de Google DeepMind permite traducción de voz instantánea y natural, soportando más de 70 idiomas con latencia mínima y tono preservado.
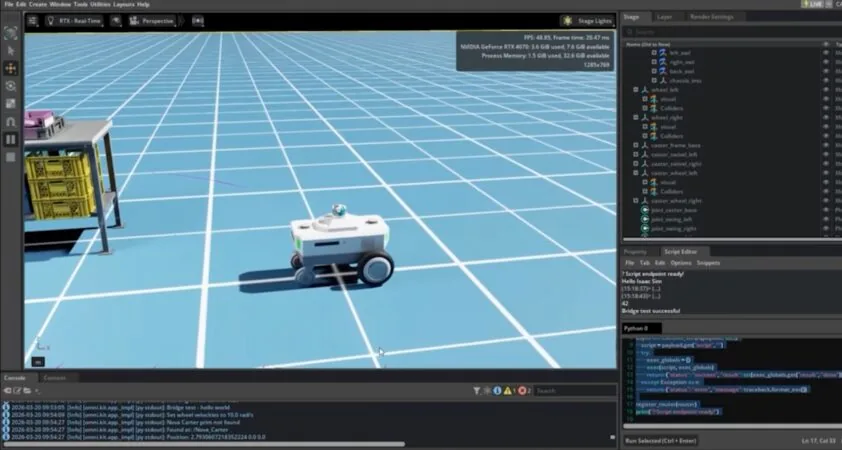
La compañía presenta capacidades avanzadas para acelerar el desarrollo de sistemas autónomos y robóticos, integrando flujos de trabajo de principio a fin.

El compilador Inductor agrupa operaciones dependientes en un solo kernel Triton, eliminando lanzamientos extra y tráfico de memoria intermedio.
Otros temas que aparecen junto a #deep learning en nuestra cobertura editorial.