
IA
FP8 y NVFP4 en Transformers: hasta 3,48x con Blackwell B300
NVIDIA muestra cómo medir GEMM por GEMM la ganancia real de las precisiones bajas en CodonFM 5B, separando el costo de cuantización del rendimiento puro del kernel.
NVIDIA Developer
4 notas publicadas
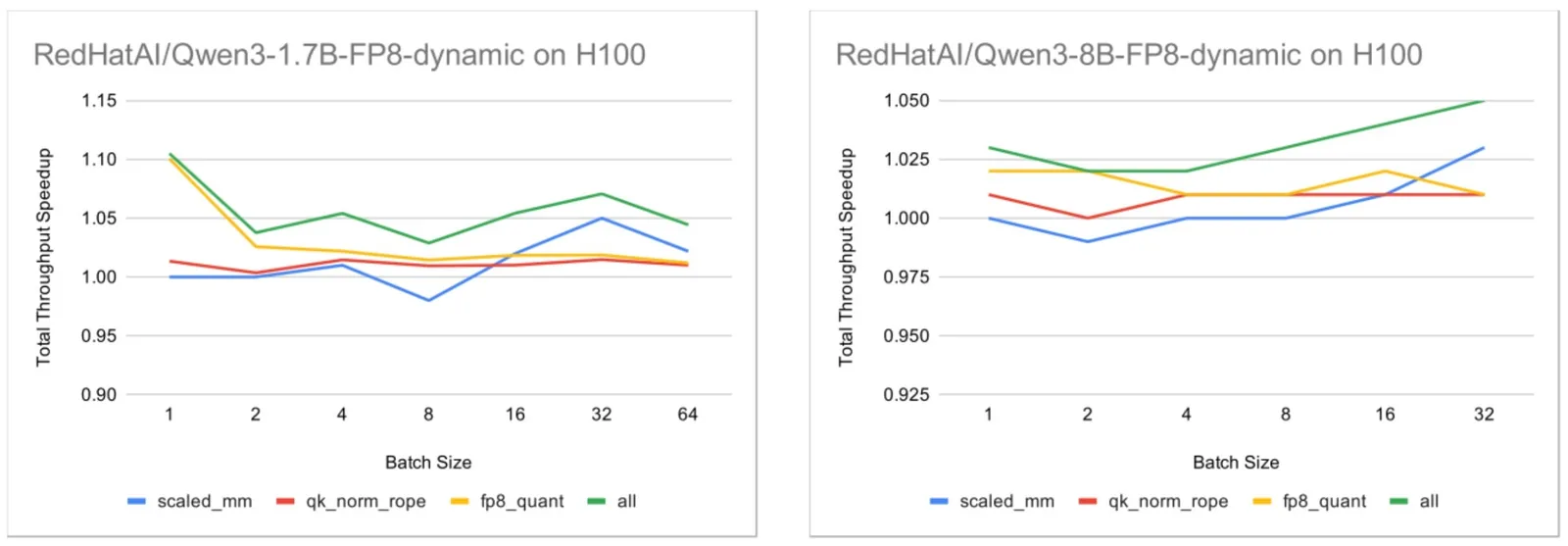
La integración con vLLM aceleró normalización, cuantización fusionada y scaled_mm en H100, mientras que B200 sigue limitado por el backend GEMM de Triton sobre Blackwell.

Receta paso a paso de post-training quantization con ModelOpt que lleva CLIP-ViT-L-14 de FP16 a FP8 sin perder calidad en clasificación zero-shot ni retrieval.

NVIDIA NeMo RL optimiza el rendimiento del aprendizaje por refuerzo mediante cuantización FP8, logrando mayor velocidad sin perder precisión en modelos de lenguaje.
Otros temas que aparecen junto a #fp8 en nuestra cobertura editorial.