Robótica
IEEE lanza programa virtual de cinco cursos sobre LLMs
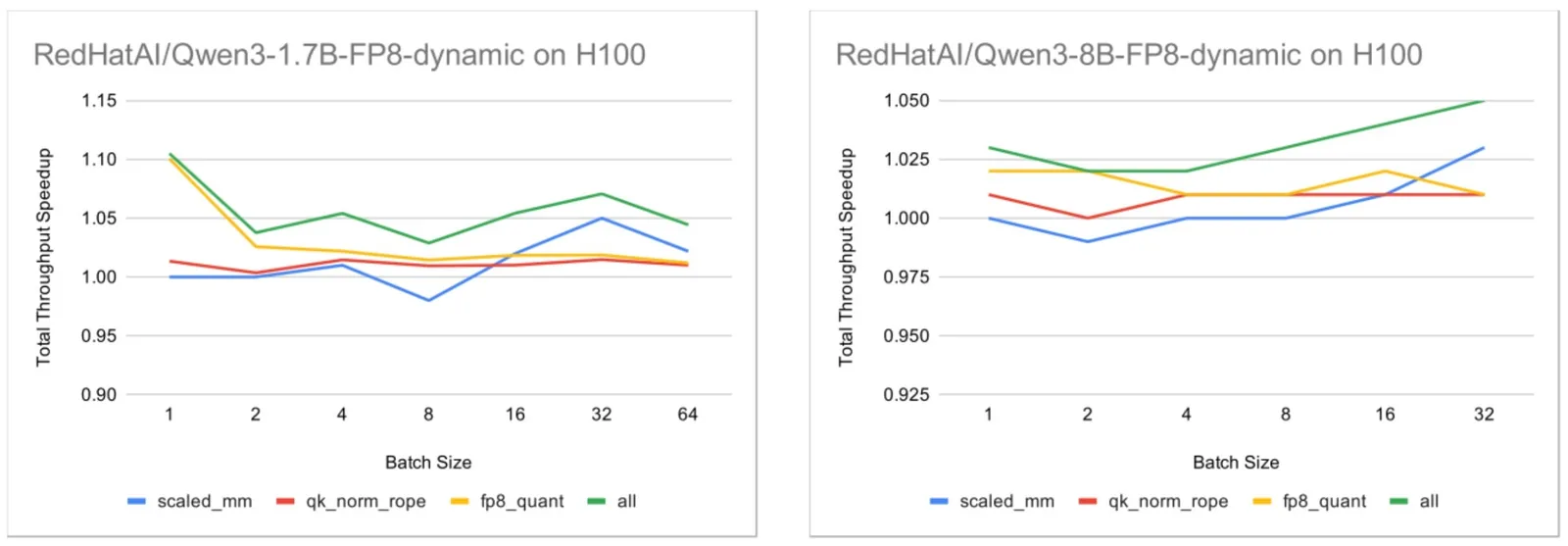
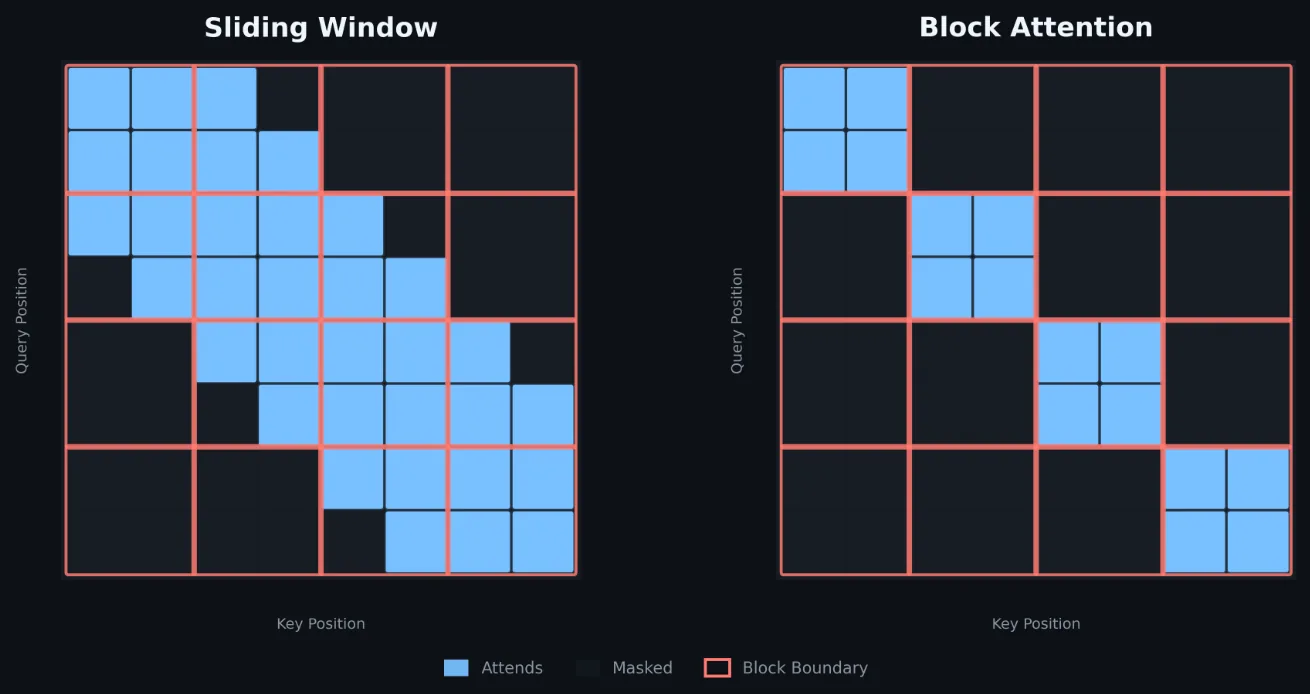
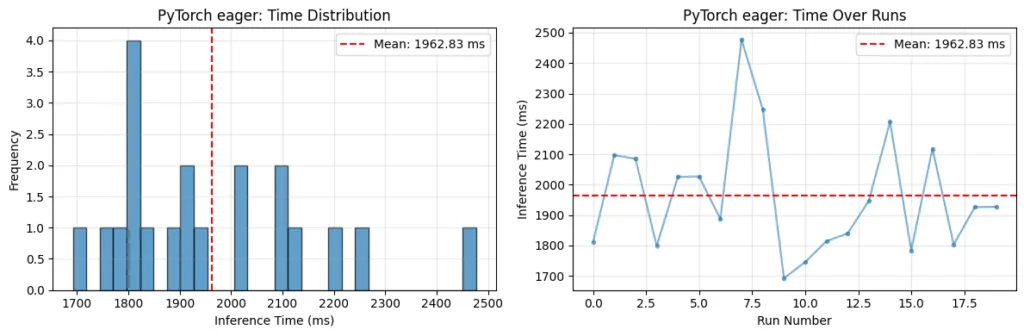
Large Language Models Demystified combina arquitectura transformer, PyTorch, LoRA, RLHF y RAG en cinco módulos online con créditos de desarrollo profesional y un badge digital.
IEEE Spectrum AI