IA
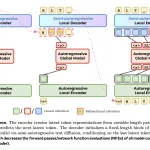
SGLang sirve DeepSeek-V4 en GB300 con 5x más throughput
Dos meses después del lanzamiento, el stack abierto pasó de 2.200 a 11.200 tok/s/GPU a la misma interactividad gracias a KV Compression V2, W4A4 MegaMoE y CUDA graphs rompibles en el prefill.
PyTorch Blog