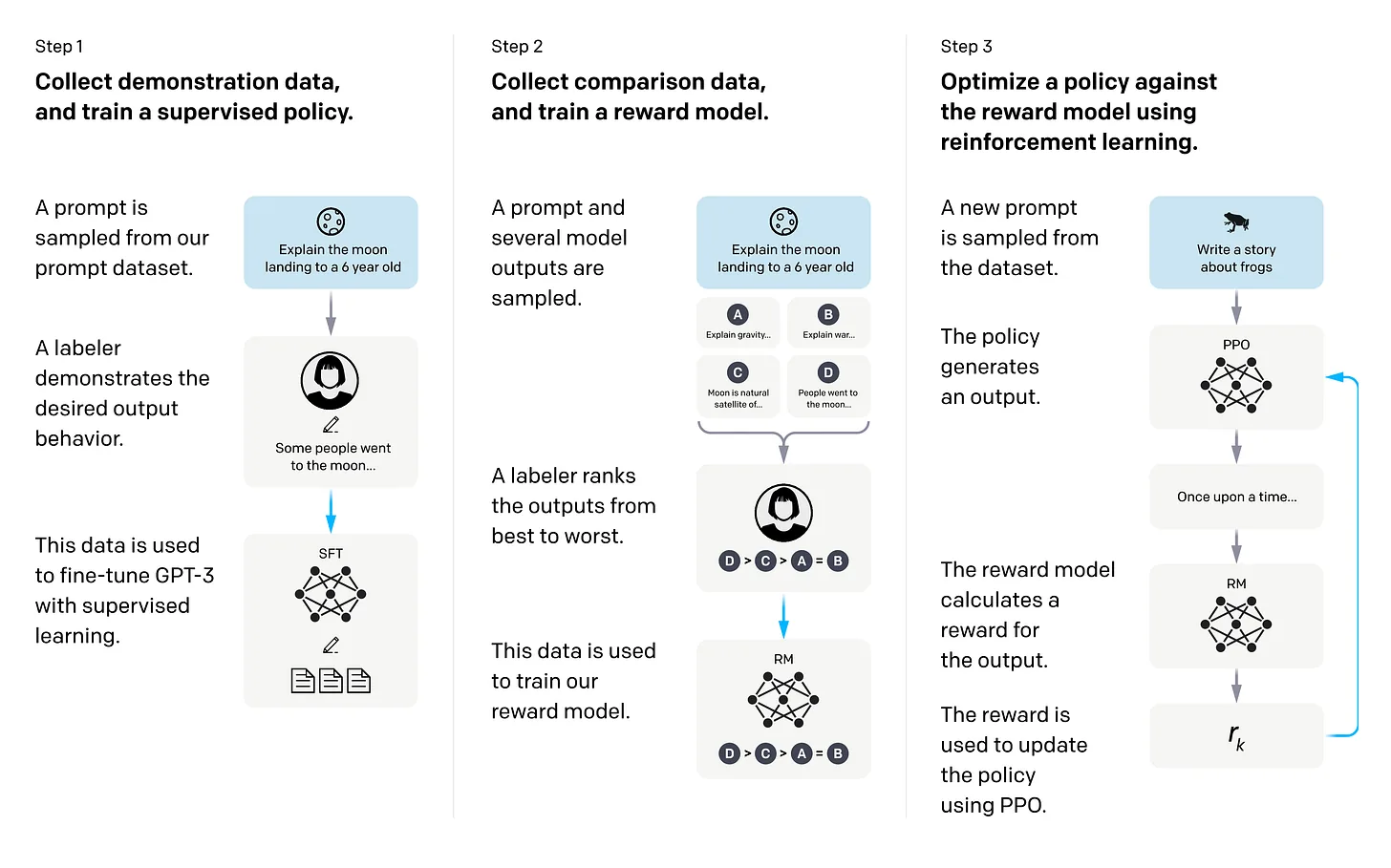
IA
NVIDIA cuantiza Nemotron 3 Ultra a NVFP4 con 5,9x más throughput
El equipo de NVIDIA reduce el checkpoint del modelo de 550B desde 1.121 GB en BF16 a 352 GB en NVFP4, con la técnica four-over-six que recupera 98,5% de la precisión sobre Blackwell.
NVIDIA Developer