
La infraestructura de IA dejó de medirse por specs de chip y pasó a medirse por costo por token: cuántos tokens útiles entrega cada dólar, cada watt y dentro del presupuesto de latencia que exige el caso de uso. Es el argumento que NVIDIA usó esta semana para presentar el estado de su stack de inferencia sobre la plataforma Blackwell, con datos concretos de la caída del costo por token en el modelo abierto DeepSeek V4.
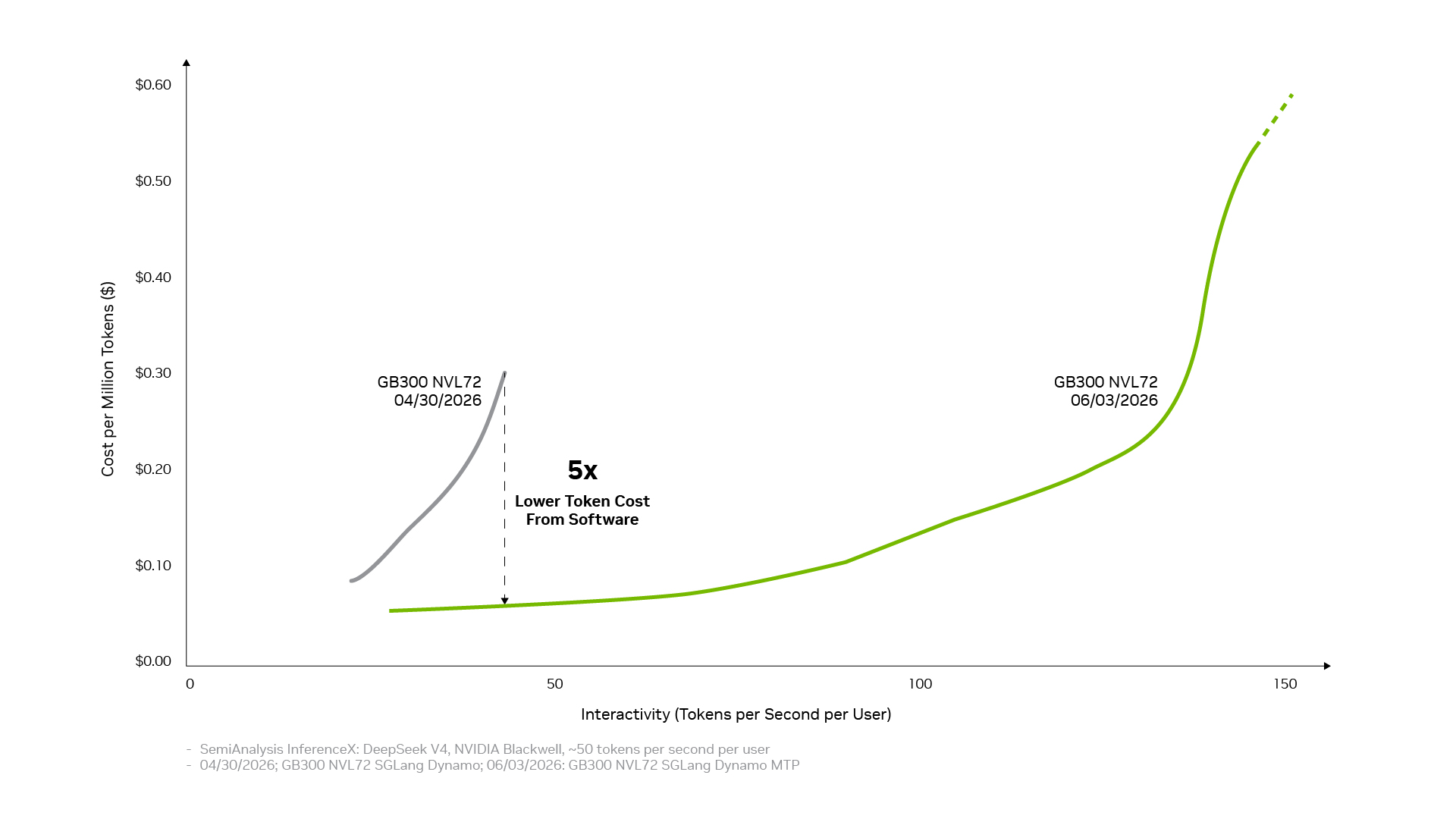
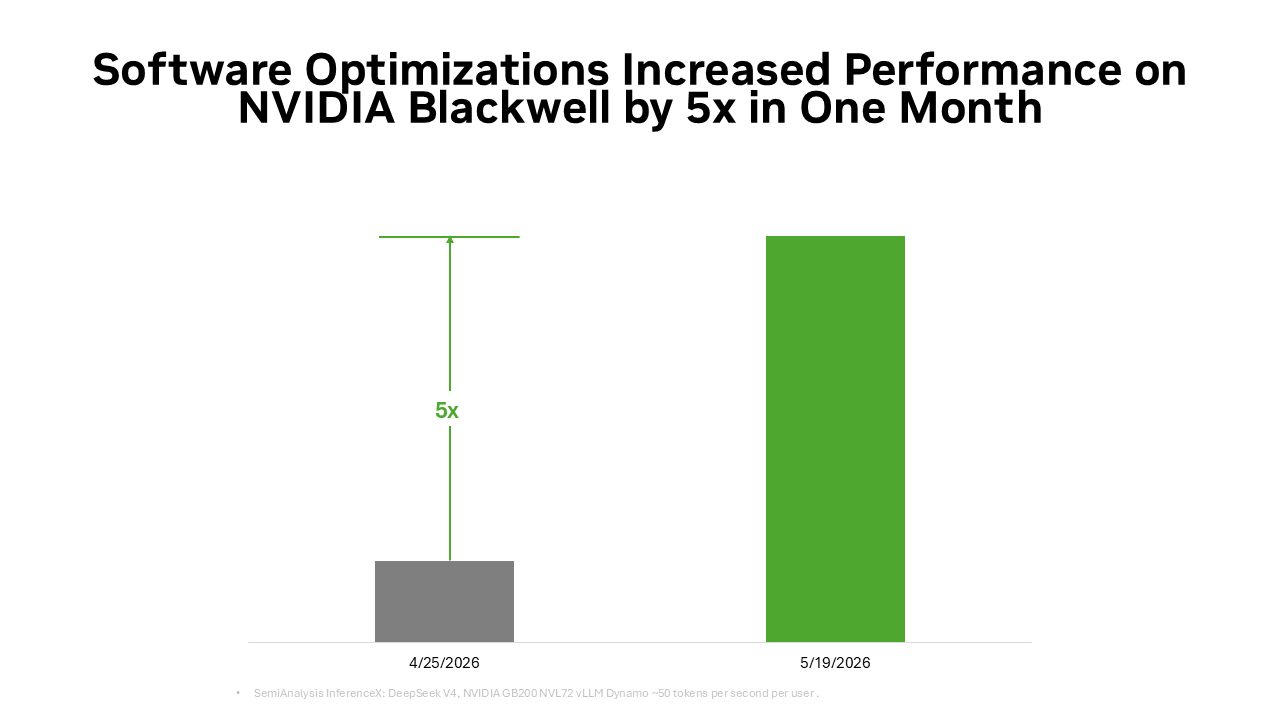
Según la compañía, en apenas un mes el software stack redujo el costo por token de DeepSeek V4 hasta 5 veces sobre GB300 NVL72, gracias a la combinación de TensorRT-LLM, el framework de inferencia Dynamo, la precisión NVFP4 y el interconector NVLink. Los datos provienen de InferenceX, el benchmark independiente de SemiAnalysis.
¿Por qué el software cambia la economía de la inferencia?
En cargas tradicionales, cada request seguía un camino predecible: leer una fila de base de datos, servir un HTML, escalar sumando más servidores iguales. La agentic AI rompe ese patrón.
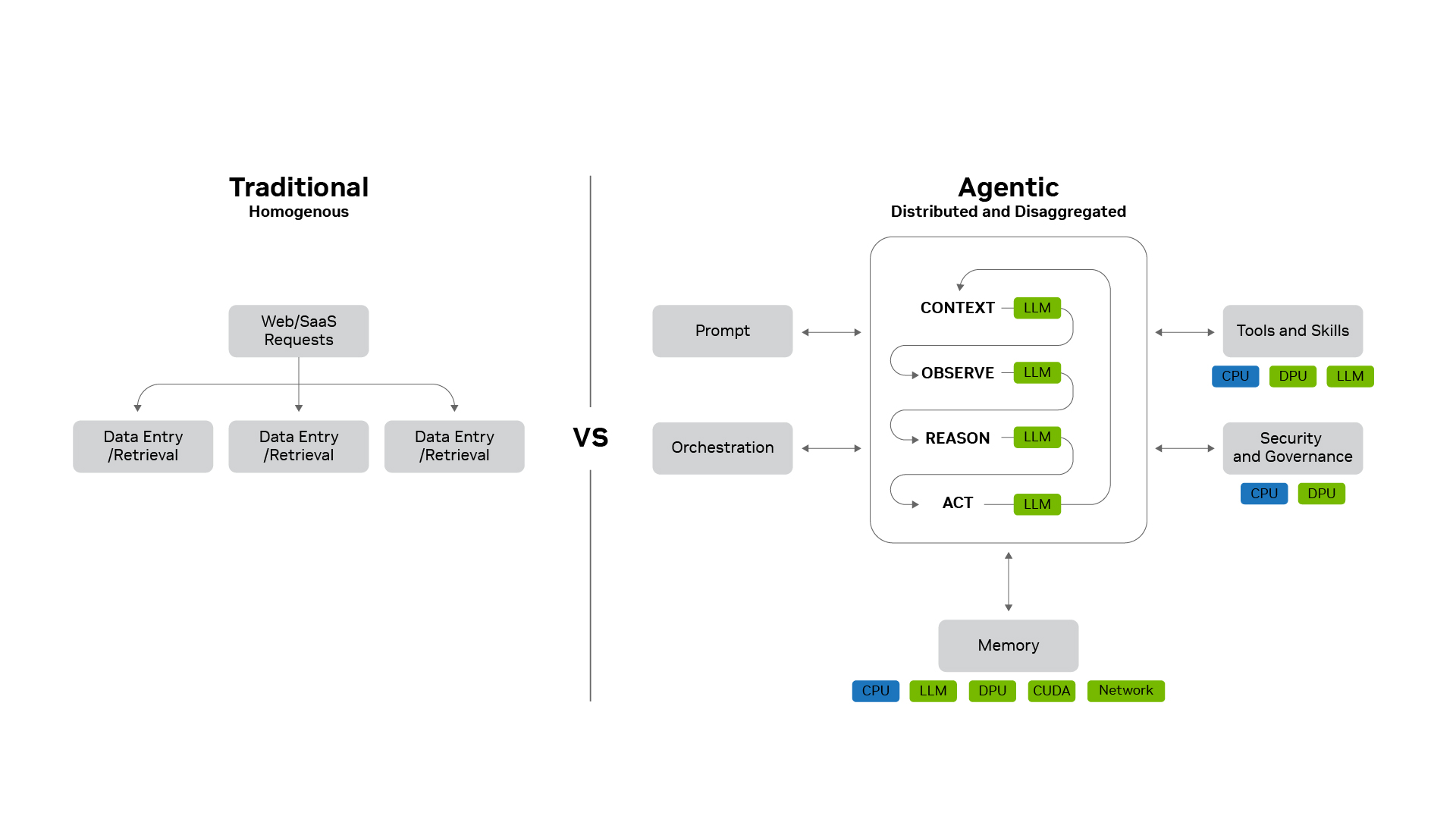
Los agentes razonan, planifican, invocan herramientas, generan subagentes especialistas y arrastran contexto masivo a lo largo de conversaciones multi-turno. Una sola consulta se convierte en un problema de cómputo distribuido que puede abarcar cientos de subagentes, miles de tareas y varios modelos grandes corriendo sobre GPUs, CPUs, DPUs y almacenamiento.
El stack de software es lo que determina si esa complejidad se traduce en capacidad desperdiciada o en costo por token más bajo. NVIDIA articula su stack en tres capas:
- Operación en producción: coordina el serving distribuido, la orquestación, el autoscaling y la gestión de memoria para repartir la inferencia entre los recursos de cómputo y storage disponibles.
- Aceleración de aplicaciones: ejecuta los modelos con alto rendimiento mientras deja espacio para tunear con optimizaciones de runtime como el solapamiento de cómputo y comunicación o el kernel fusion.
- Acceso a infraestructura: expone GPUs, red, memoria y capacidades de sistema sin obligar al desarrollador a lidiar con cada instrucción de bajo nivel.
Serving desagregado y NVFP4: cuando las optimizaciones se apilan
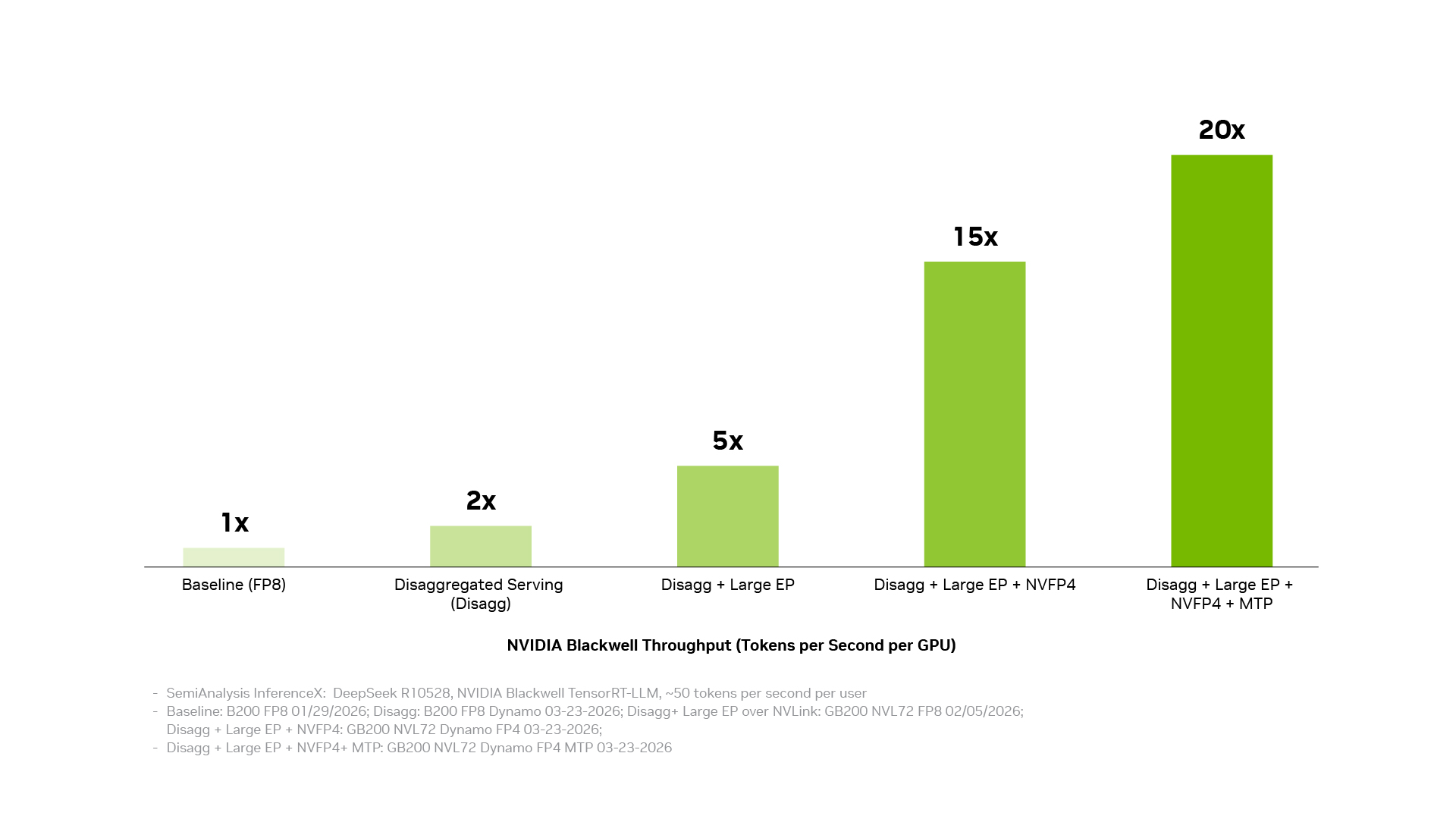
Cuatro técnicas concretas explican el salto de rendimiento: el serving desagregado, la paralelización de expertos a gran escala sobre NVLink, la precisión NVFP4 y la multi-token prediction. Cada una entrega ganancias significativas por separado, pero al combinarlas el throughput sube hasta 20 veces por GPU respecto a la línea base.
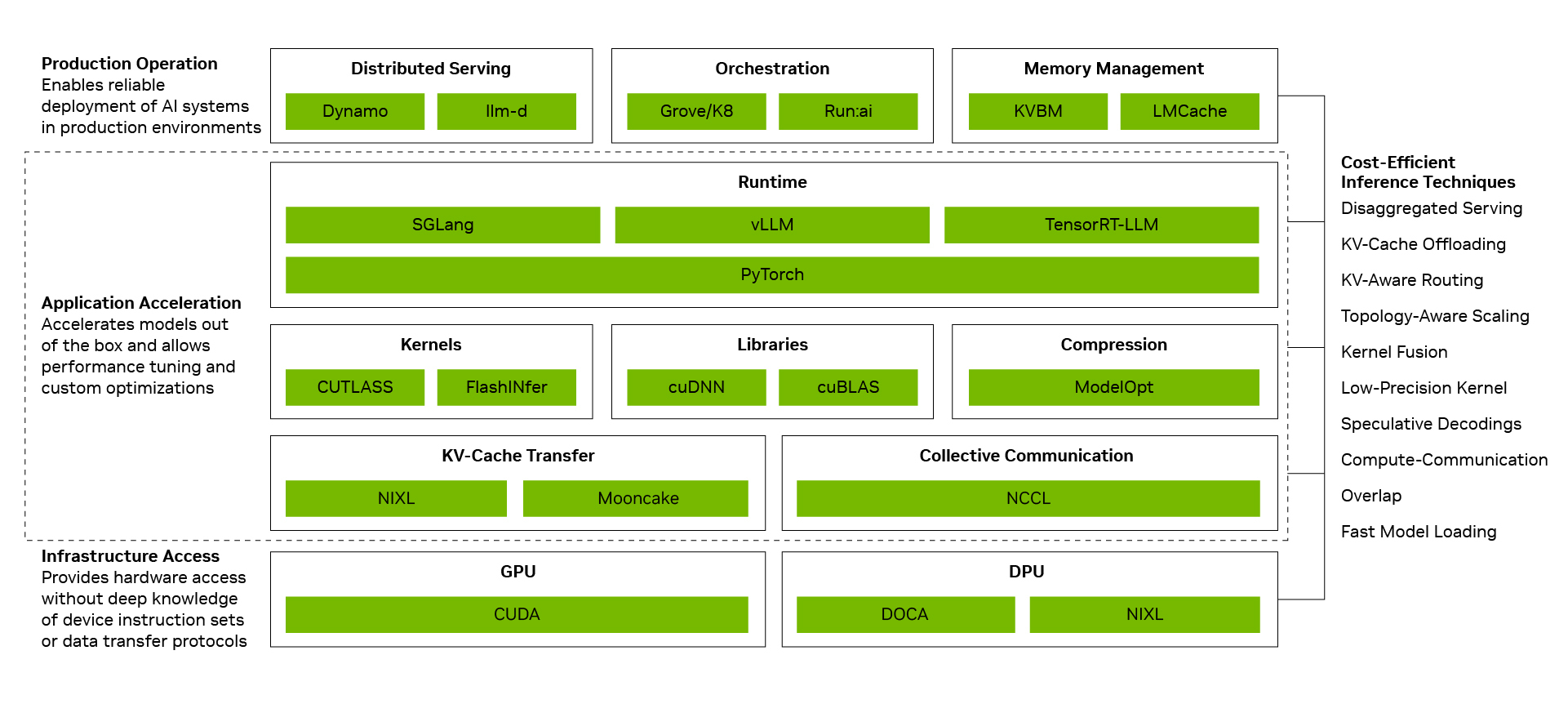
Capturar esa ganancia en producción es complejo: exige coordinación de toda la pila, desde las operaciones de producción y los runtimes de modelo hasta los kernels, las librerías de comunicación y el acceso a hardware. El punto de NVIDIA es que su stack está diseñado para que esas capas se refuercen entre sí.
El efecto del ecosistema open source
La segunda pata del argumento es CUDA. Muchos de los frameworks abiertos más usados están construidos de forma nativa sobre CUDA, así que cada mejora en investigación llega con rendimiento líder desde el día cero sobre GPUs NVIDIA.
PyTorch es el ejemplo canónico. Lanzado en 2016 con soporte nativo de CUDA, coevolucionó con la arquitectura de NVIDIA y hoy entrega Tensor Cores, Transformer Engine y NVFP4 directo desde su API. Cuando aparecen avances como DFlash speculative decode, que llega a multiplicar por 15 el throughput sobre hardware existente, o FastVideo, que genera video 1080p en menos de cinco segundos, corren de inmediato sobre NVIDIA.
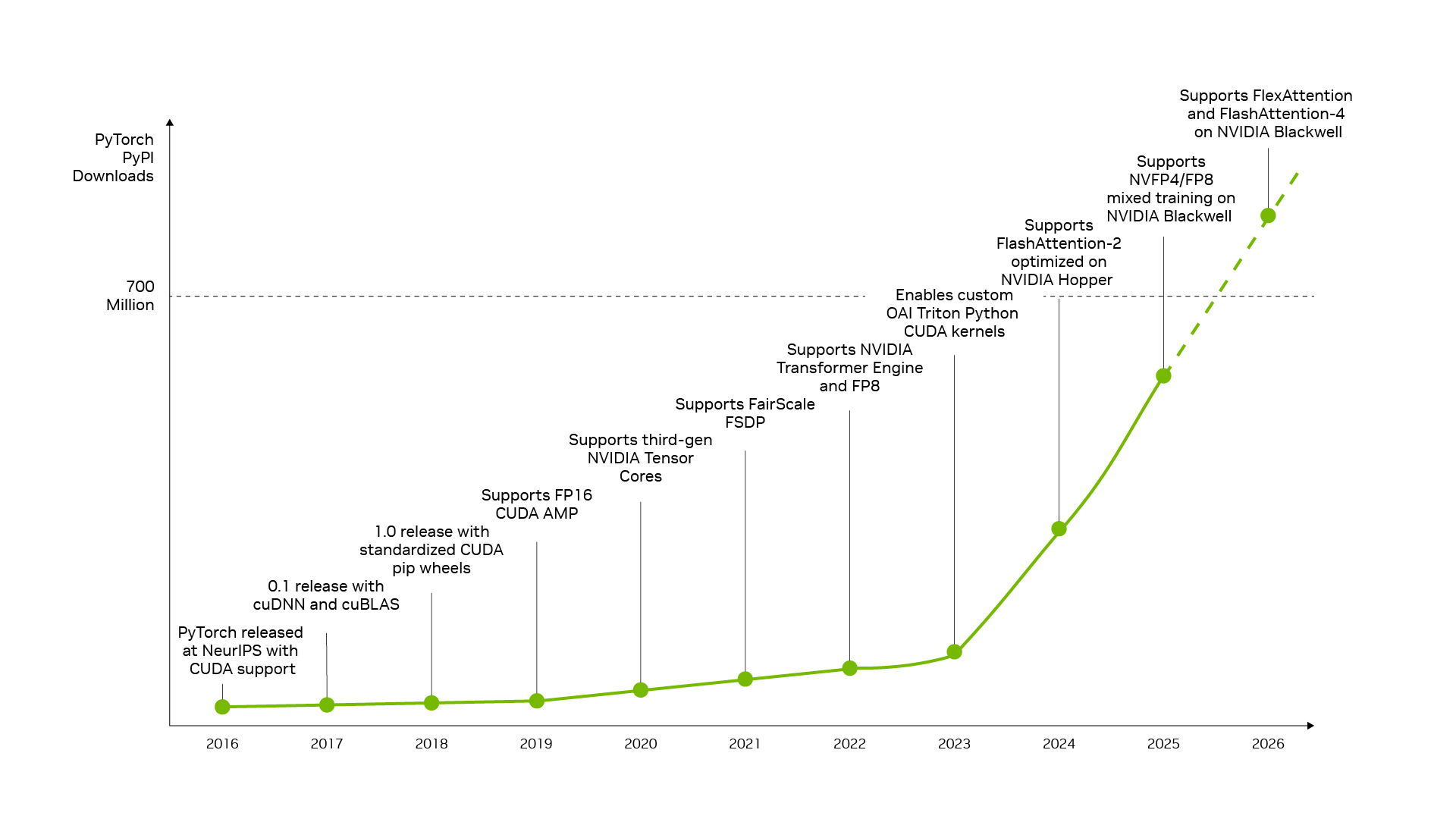
Ese mismo empuje explica por qué los frameworks de inferencia como vLLM y SGLang tuvieron recetas de despliegue day-zero para Blackwell cuando salió DeepSeek V4, y por qué el rendimiento del modelo sobre Blackwell mejoró hasta 5x en un mes en ambos frameworks, cortando el costo por token a aproximadamente un quinto de su nivel previo.
¿Qué implica para operadores en la región?
Para integradores y proveedores de infraestructura de IA en LatAm el punto operativo es concreto: Blackwell no es una decisión de hardware aislada. La eficiencia real depende de qué tan al día esté el stack de software (Dynamo, TensorRT-LLM, NVFP4, vLLM, SGLang) sobre las GPUs alquiladas u operadas. Un mes de retraso en updates puede significar pagar 5 veces más por el mismo throughput.
Casos citados por NVIDIA que ya operan sobre este stack: Baseten logró servir DeepSeek V4 Pro con TensorRT-LLM y sumar hasta 50% más tokens por segundo; DigitalOcean ayudó a Hippocratic AI a subir 30% el throughput manteniendo latencia bajo medio segundo en 10 millones de llamadas médicas; Together AI ayudó a Cursor a acortar el camino entre optimización y endpoint productivo.



